Tu sú vypracované otázky k predmetu SWI004... Originálna verzia (pravdepodobne zozbieraná z rôznych zdrojov) je z http://gask.oktawa.net/QU.html .
Pozor !!! Jde pouze o Questions, Excercices tu chybi.
Process Alone
Explain what is a process.
proces je abstrakce, pokud nemáme vlákna, můžeme brát za proces spuštěný program (tj. program nahraný do paměti) a stavy zdrojů jenž využívá
pokud máme vlákna, tak proces může být brán jako pasivní obal (tj. sám o sobě neběží), který obsahuje vlákna.
instrukce, registry, paměť
někdy má vlastní virtuální adresový prostor
Explain how the operating system or the first application process gets started when a computer is switched on.
v HW (procesoru) je napevno zadrátovaná adresa, od které se začínají vykonávat na CPU instrukce
=> tzv. bootstrap program, vypálený typicky v některé z pamětí (eprom, rom, apod.)
bootstrap inicializuje HW, načítá program code a statické proměnné, tzv. program image (image dalšího programu)
EDIT: Otázka je, jak se tam dostane OS. Bootstrap načte většinou jen další zavaděč někde na začátku disku. Ten pak načte zavaděč z oddílu(protože ten tupý zavaděč BIOS nemá drivery pro file systémy a neví, kde má najít boot oddíl), a ten teprve slavnostně načte zavaděč pro OS. Je to proto, že boot sectory jsou většinou fixní a krátké.
Explain what it means to relocate a program and when and how a program is relocated.
absolutní adresování - adresy v programu jsou zapsané přímo absolutní hodnotou - problém nastává, když se program nenahrává na stejné místo v paměti
relokace - proces úpravy image programů, tak že posune jednotlivé adresy programu o daný offset (podle toho, kam se program nahraje)
?program se relokuje při zavedení programu do paměti?
samotná relokace spočívá v tom, že se z fixup table berou jednotlivé odkazy do kódu na adresy, které je třeba změnit a k nim se připočte base register
pokud má každý proces virtuální adresový prostor, tak se samotný program relokovat nemusí (např. program začíná vždy na adrese 0x0)
vs.
relativní adresování - adresy v programu jsou psány stylem adresa + offset podle globální tabulky symbolů vzniká nám tak position independent code, ale vzniká tak více instrukcí
EDIT: Kdy se to dělá? Tak u sdílených knihoven je občas nutnost mít je na jiných adresách, třeba proto, že se bijí s jinými knihovnami. A další důvod je randomizace, pro zabránění útoků. Když chce útočník skočit na fixní adresu, kde očekává specifický kód.
Explain what information is needed to relocate a program and where it is kept.
fixup table – tabulka s pointery na adresy v kódu, kde je třeba opravit při relokaci adresy
může se nacházet v hlavičce obj file, sama tabulka je relativní, takže i pointery v ní musí být pozměněny
může se nacházet v sekci binárky, například ve formátu ELF v části .rel
mrkněte sem: http://www.linuxforums.org/articles/understanding-elf-using-readelf-and-objdump_125.html
Explain what it means to link a program and when and how a program is linked.
merge obj souborů, každý poskytuje tabulku symbolů
resolve externals - znamená průchod tabulkami a nahrazování referencí z jednoho souboru do druhého
relocate symbols – konečná relokace souborů
statické linkování - při překladu souboru se nahraje celá knihovna k binárce a patřičně se upraví tabulky symbolů
dynamické linkování - při překladu se k binárce dají pouze tabulky symbolů, vlastní překlad tabulek symbolů probíhá až při spuštění, za nahrávání knihoven je zodpovědný dynamic loader - součást OS
Explain what information is needed to link a program and where it is kept.
tabulka s informacemi, které symboly které obj soubory poskytují a kde se uvnitř nacházejí
ve formátu binárky ELF jsou to např. sekce symtab a dynsym pro statické a dynamické linkování
Explain what the interface between processes and the operating system looks like, both for the case when the operating system code resides in the user space and for the case when the operating system code resides in the kernel space.
volání systému jsou zabalena do knihovních funkcí, takže se používají v kódu jako klasické funkce
syscall je speciální rutina s vyššími právy, volaná většinou kódem s nižšími právy, obsahuje kontrolu zda vůbec dovolí rutinu spustit
samotný syscall – například uložení číslo volané služby do registru a vyvolání přerušení, popřípadě vykonání speciálních instrukcí sysenter a sysexit
rozhraní musí být efektivní (rychlé přepínání módů), robustní (kvůli škodlivému kódu - raději hodně funkcí, než nějaký bezpečnostní hacky) a flexibilní (aby se později při přidání nových služeb nemuselo měnit)
Propose an interface through which a process can start another process and wait for termination of another process.
POSIX
pid_t fork(void) - rodič forkuje, potomek, ale pořád vykonává kód rodiče
int execve(const char *filename, char *const arvg[], char *const env[]) - potomek začne vykonávat kód programu (kód rodiče je přepsán nově nataženým ze souboru, vrací hodnotu pouze při chybě
pid_t wait (int *stat_loc) - čeká na ukončení libovolného synovského procesu a vrací jeho pid, případně značí chybu, status = adresa kam nahrát návratovou hodnotu
pid_t waitpid (pid_t id, int *stat_loc, int options) - obecnejsi verze volani, da se pres ni naprogramovat wait
void exit(int status) - ukoncuje proces zapisuje navratovnou hodnotu (0 = OK, cokoliv jineho chyba)
WIN
bool CreateProcess(), WaitForSingleObject(PID, timeout)
Achieving Parallelism
Explain how multiple processes can run concurrently on a single processor hardware.
multiprocessing – OS umí pustit proces a po určité době ho odstavit, uloží jeho stav/kontext (PC, registry, stack pointer), flushne TLB nebo lépe změní ASID pro nový proces, načte jeho kontext a pustí jej.
je-li střídání dostatečně rychlé, nastává iluze více běžících procesů zároveň
Explain what is a thread and what is the relationship between threads and processes.
vlákno je běžící program, aktivita uvnitř procesu, akt vykonávání programu
proces je pasivní obálka, poskytující běžícím vláknu uvnitř zdroje, kód a paměť
vlákna jsou vykonávané instrukce uvnitř procesu, vláken v jednom procesu může být více, sdílejí paměť a kód, ale mají každé svůj vlastní zásobník a popřípadě i thread local storage.
Explain what happens when the thread context is switched.
kontext přepíná zásadně operační systém (čti kód v operačním systému)
při přepnutí kontextu vlákna uloží operační systém CPU kontext (global purposes registers, flags, stack pointer, program counter) - ukládá ho většinou na stack. Následně se přepne na stack nově naplánovaného threadu, nahraje si z něj registry a pokračuje dále. EDIT: Pozor, také se musí přepínat virtuální paměť, pokud jej thready nesdílí (tedy jsou ty thready z jiných procesů například). Ale to už není tak moc o context switchy ale o přeplánování. Proto bych to raději nepopisoval tak vágně.
v principu tedy pouze přepnutí na jinou sadu registrů
Některé procesory mají několik speciálních instrukcí, které přepnutí značně urychlí - intel
Jiné procesory na to nejsou příliš optimalizované - mips
EDIT: Speciální instrukce pro context switch na procesoru se hodí především proto, že se často různé verze liší počty a typy registrů. Proto, aby to OS nemusel tak složitě handlovat a byla tam zpětná kompatibilita, usnadní ty speciální instrukce život.
Explain what happens when the process context is switched.
během volání OS je uložen program counter na zásobník, procesor uklácá originální hodnotu na zásobník toho procesu, který bude odstaven
OS se ujme řízení, uloží ostatní registry na zásobník odstavovaného procesu
OS přepne zásobník na zásobník procesu který bude pokračovat v běhu
ze zásobníku se obnoví registry CPU
přepnou se "process dependent" datové struktury, tedy mapování stránek, mapy zdrojů užívaných aktuálním procesem, flushnutí TLB a ostatních cache, etc.
EDIT: K tomu výše. To tak úplně není pravda. Context switch není nutně přeplánování, je to mnohem obecnější pojem. Může jít o nutnost vyřídit interrupt nebo přímo syscall. Ale také o přeplánování. Pokud se tedy do toho vlákna zase vrátím, není nutné mu flushovat TLB (tedy ani měnit process dependent struktury). To se pak týká přeplánování, a ani tam není nutné flushovat TLB, máme-li něco jako ASID. A po každém switchy vypláchnout cache? To by bylo zlý. Zajímavost, pokud jen handluju interrupt, tak se dokonce ani všechny registry nemusí zálohovat. Například některé extended 128bit registry atd. se neočekávají, že by handler potřeboval. Pokud ano, vyvolá se výjimka a teprve potom se to douloží.
jako poslední se obnoví PC, tedy ukazatel na instrukci, kterou se bude pokračovat v běhu programu, na jehož kontext OS právě přepnul
Using a step by step description of a context switch, show how an implementation of threads in the user space and an implementation of threads in the kernel space differ in the way the context is switched. Na popisu přepnutí kontextu krok po kroku ukažte, jak se implementace vláken v uživatelském prostoru a implementace vláken v prostoru jádra liší ve způsobu přepínání kontextu.
user threads – uživatelem naprogramovaná vlákna, může být součástí aplikace
výhody: šetří se režie na volání kernelu, šetří se paměť kernelu, lze naimplementovat „na míru“, přepínání vláken může být kooperativní
nevýhody: pokud některé vlákno zavolá kernel a zůstane v něm, nemá kdo by vlákno přepnul na jiné, protože aplikace co uživatelská vlákna přepíná se nedostane k lizu; thready nemůžou bez podpory kernelu využívat více procesorů
kernel threads – vlákna uvnitř kernelu, nebo vlákna spravované kernelem, které používá aplikace
výhody: lze uzpůsobit plánování vláken na konkrétní procesory, není problém s odnímáním běhu jednotlivým vláknům (spravuje je přeci kernel), není problém s reentrantností knihoven (malloc apod.)
nevýhody: je to napevno navržené, nelze doimplementovat další fíčury, musí to být opravu bulletproof (pokažený thread v jvm vs. pokažený thread v kernelu)
Explain how the requirements of interactive and batch processes on the process scheduling can contradict each other.
Interaktivní procesy většinu času čekají na vstup a nic nedělají, ale pokud se něco stane, na co mají reagovat, musí se ke slovu dostat rychle. Naproti tomu, akce, kterou musí provést je typicky nenáročná a stačí jim kratší kvanta. Dávkové procesy to mají přesně naopak. Většinu času něco počítají a, aby pracovaly trochu efektivně (měly data v cache apod.), potřebují, aby je chvilku nikdo nepřerušoval -> vyžadují delší kvanta. Na druhou stranu nepotřebují být plánovány rychle.
List the typical requirements of an interactive process on the process scheduling.
responsiveness – reakce na to, že se něco děje, reakce na asynchronní události – user input, network requests apod.
fairness – spravedlivost, procesy s podobnými parametry (priorita, časové kvantum) budou také podobně plánovány a žádný nebude upřednostněn
List the typical requirements of a batch process on the process scheduling.
efficiency – efektivní využití a rozložení zdrojů (například plánování procesů na více procesorů)
List the typical requirements of a realtime process on the process scheduling.
predictability – předvídatelnost, systém garantuje určité chování scheduleru, je důležité pro realtime aplikace
turnaroud – co nejmenší délka úlohy, aby nikdo neblokoval ostatní
Explain the difference between soft and hard realtime scheduling requirements.
hard realtime – úloha se MUSÍ stihnout do daného limitu - Příklad: algoritmus pro ABS, řídící systém družice.
soft realtime – úloha se musí stihnout do daného limitu, ale je povolen statistický limit prošvihnutí úloh (třeba jedna úloha ze sta) - Příklad: Přehrávání videa.
Define typical phases of a process lifecycle and draw a transition diagram explaining when and how a process passes from one phase to another.
init; runing in kernel (return) running in user mode (syscall, int) running in kernel (quantum expires, yield) ready (schedule) running in kernel (wait) waiting (end of wait) ready; zombie
na 6. strane je pekný obrázok (stavový diagram) stavov v linuxe
lépe je to videt v materiálech k Úvodu do Unixu, je tam i hezky obrázek, který se hodí k popisu inodu
Explain cooperative context switching and its advantages.
procesy se střídají na procesoru tak, že se každý vzdá po určité době běhu sám
výhody: menší režie, nejsou nevhodná přeplánování
Explain preemptive context switching and its advantages.
procesy se střídají na procesoru, ale plánovač má možnost po době dané časovým kvantem každého procesu mu CPU odebrat
výhody: nikdo si neuzurpuje CPU, robusntější systém odolný proti záměrně „náročným programům
Explain the round robin scheduling algorithm by outlining the code of a function GetProcessToRun that will return a process to be scheduled and a time after which another process should be scheduled.
kruhová fronta ready to run procesů, plánovány jsou ty ze začátku fronty, po ukončení nebo vypršení časového kvanta jsou řazeny na konec
GetProcessToRun ( pid = get_first_in_queue_and_rotate(); shedule(pid); )
Explain the simple priority scheduling algorithm with static priorities by outlining the code of a function GetProcessToRun that will return a process to be scheduled and a time after which another process should be scheduled.
více round robin front, pro každou prioritu třeba dvě, když je program přeplánován před vyčerpáním časového kvanta, je zařazen do active fronty, když vyčerpá, je zařazen do expired fronty
vybírá se z fronty s nejnižší prioritou, nejprve z active, potom z expired
pokud je active prázdná a v expired něco je, fronty se prohodí, přejmenují
Processes are assigned static priorities, the process with the highest priority is scheduled.
Either constant quantum is used or shorter quantum is coupled with higher priority and vice versa.
Explain the simple priority scheduling algorithm with dynamically adjusted priorities by outlining the code of a function GetProcessToRun that will return a process to be scheduled and a time after which another process should be scheduled.
pro každou prioritu jedna fronta, když je program přeplánován před vyčerpáním časového kvanta (chce běžet déle), je posunut nahoru (zvášení priority, interaktivní procesy, žádají o IO), pokud se přeplánuje po vypršení kvanta (chce běžet dlouho), potřebuje delší kvantum, zařadí se o patro níž (kvantum zvýšeno, priorita snížena, mezi procesy co chtějí CPU)
Processes are assigned initial priorities, actual priorities are calculated from the initial
priorities and the times recently spent executing, the process with the highest actual priority is scheduled.
Explain the earliest deadline first scheduling algorithm by outlining the code of a function GetProcessToRun that will return a process to be scheduled and a time after which another process should be scheduled.
tupě prioritní round robin, proces s nejnižší deadline vždy musí doběhnout jako první, bude se tedy řadit dle deadline
Procesy mají deadlines do kdy musí nˇeco udˇelat, plánuje se vždy proces s nejbližší
deadline. Deadlines se zpravidla rozdˇelují do hard realtime deadlines , ty jsou krátké a nesmí se prošvihnout, soft realtime deadlines , ty jsou krátké a obˇcas se prošvihnout
m°užou dokud bude možné zaruˇcit nˇejaký statistický limit prošvihnutí, timesharing deadlines , ty v podstatˇe nemají pevný ˇcasový limit alemˇely by se do nˇekdy stát, batch
deadlines , ty mají limity v hodinách a obvykle s nimi nebývají problémy.
Explain the function of the Solaris process scheduler by describing how the algorithm decides what process to run and for how long.
priority 0-160, pro každou round robin,
timesharing, interactive a realtime classes
kernel je mostly preemptive
timesharing: 0-59 (nižší priority mají delší kvantum), priorita se zvyšuje při čekání na něco nebo když proces nespotřebuje své kvantum, priorita se snižuje po spotřebování kvanty, změny priority určuje tabulka
system stejné jako timesharing, 60-99
realtime 100-159
vybírá se proces s nejvyšší prioritou
poskytuje volání, které požádá kernel o dočasné neodebírání procesoru
Explain the function of the Linux process scheduler by describing how the algorithm decides what process to run and for how long.
časová složitost plánovače je O(1)
priority 1-140 , pro každou dvě round robin fronty (active a expired)
program je v active frontě, pokud byl odstaven před vypršením svého kvanta,
po vypršení kvanta je v zařazen do expired fronty
vybírá se fronta s nejnižší prioritou, active fronta má přednost před expire
je-li active fronta prázdná a v expired něco je, fronty se prohodí
podpora metriky pro interaktivitu – počítá se podle toho, jak dlouho proces čeká na IO; ty co čekají na IO jsou odměněny, ty které chtějí hodně počítat jsou penalizovány
program co čeká na IO se z active fronty nevyhazuje
Explain the function of theWindows process scheduler by describing how the algorithm decides what process to run and for how long.
třídy priorit IDLE, NORMAL, HIGH, REALTIME
uvnitř každé třídy relativní priorita IDLE, LOWEST, BELOW_NORMAL, NORMAL, ABOVE_NORMAL, HIGHEST, TIME_CRITICAL
formule pro určení definitivního numera pro prioritu není rozumně hezká
perlička – třídy normal obdrží boost při přepnutí na foreground
plánuje se thread s nejvyšší prioritou, na stejné prioritě funguje round robin
zohledňuje se afinita na SMP
plánují se thready, nikoli procesy
priority TIME_CRITICAL smějí uzurpovat procesor
datové struktury: round robin pro každou prioritu, 32-bitová maska označující neprázdné fronty, 32-bitová maska volných CPU
Define processor affinity and explain how a scheduler observes it.
svázanost procesu k procesoru – pokud proces běžel na nějakém CPU, v registrech, cachích apod. zůstala pravděpodobně užitečná data. Proto je vhodné při dalším plánování toho procesu jej umístit na naposledy navštívený CPU
scheduler si může pamatovat, kam který proces umístil
Windows: každé vlákno má dvě čísla – ideální CPU (generováno třeba náhodně při vzniku) a poslední CPU (dle toho, kde vlákno běželo). Kam naplánovat? Pokud je nějaký CPU volný, plánuje se v pořadí ideální – poslední – aktuální – libovolný. Pokud není volný CPU, hledá se vhodná oběť – ideální – poslední – nejvyšší z možných.
Propose an interface through which a thread can start another thread and wait for termination of another thread, including passing the initial arguments and the termination result of the thread.
například Windows:
HANDLE CreateThread(...)
parametry: start address, stack size, argumenty, flags
WaitForSingleObject(...)
nebo viz semestrálka
int thread_create (thread_t * thread_ptr, void (* thread_start) (void *), void * data)
int thread_join (thread_t thr)
int thread_join_timeout (thread_t thr, const unsigned int usec)
Process Communication
Propose an interface through which a process can set up a shared memory block with another process.
int shmget (key_t key, size_t size, int shmemflag)
allocates a shared memory segment
vrací identifikátor segmentu sdílené paměti asociované s argumentem key
void *shmat (int shmid, const void *shmaddr, int shmemflag)
attaches the shared memory segment identified by shmid to the address space of the calling process.
připojuje sdílenou paměť identifikovanou shmid do adresového prostoru volajícího procesu (attach)
int shmdt(const void *shmaddr)
detachuje sdílenou paměť
Define synchronous and asynchronous message passing.
synchronní - procedura co zprávu poslala nemůže pokračovat, dokud jí nedojde odpověď
asynchronní – procedura nečeká na doručení zprávy a může pokračovat, aniž by dostala odpověď
EDIT: Nevím, proč je to v poznámkách formulováno takhle nešťastně. Ale reálně to mělo znamenat toto.
synchronní - procedura co zprávu poslala vyžaduje odpověď - je jedno, jestli se blokne nebo ji dostane callbackem.
asynchronní – procedura nečeká na doručení zprávy.
Sémantika je asi jasná, že pokud čekám na odpověď, tak bez ní nepokračuji dále jako kdybych měl jistotu že došla. Ale není nutné, aby synchronní volání bylo blokující.
Define blocking and non blocking message sending and reception.
blokující – procedura co zprávu odeslala nebo obdržela čeká na vyprázdnění odesílacíhu bufferu, než může skončit
neblokující – čekání po odeslání nebo přijetí není možné
EDIT: Tohle je také nějaké zmatené. Navíc se bavíme dosti v obecné rovině. Správně by to podle mě mělo být takto.
blokující – procedura se muže bloknout čekáním na odpověď.
neblokující – procedura se nesmí blouknout čekáním na odpověď.
A pokud chci mít proceduru, která není blokující, ale chci čekat na odpověď tak mám jako možnost callback či polling (periodicky se ptám na výsledek).
Explain how polling can be used to achieve non blocking message reception.
neustále odesílatele dráždím, jestli už něco poslal
mohu mít tedy blokující proceduru, ale ta je bloknutá jenom po dobu co se ptám. Potom vykonávám něco jiného a po chvilce se opět zeptám, jestli už je zpráva pro mne připravena
EDIT: Tady bych tedy neřekl, že "dráždím" odesílatele. Spíše se dotazuji komunikačního frameworku na mé straně, jestli pro mě již eviduje nějakou odpověď od odesílatele. To by byl šílený overhead, pokud bych se odesílatele neustále ptal, jestli už pro mě má odpověď.
Explain how callbacks can be used to achieve non blocking message reception.
ve správě kterou odešlu specifikuji svou funkci nebo proceduru
jakmile zpráva adresátovi dorazí, zavolá mi přes RPC mojí proceduru
přidám svůj názor (ne možná zcela správný): při zavolání procedury čtení zprávy je v rozhraní této procedury pointer na callback funkci, která bude zavolána v okamžiku přijetí zprávy. Tím pádem se můžu okamžitě vrátit a vlastní přijetí zprávy mi bude oznámeno právě vykonáním callback funkce (typické je ve Widličkách nastavení eventu), ale může se jednat o v podstatě libovonou akci.
Explain when a synchronous message sending blocks the sender.
odesílatel odešle zprávu a ta nedorazí příjemci
Explain when an asynchronous message sending blocks the sender.
odesílatel pošle zprávu, ale ta (vinou nějaké chyby) odesílatele ani neopustí
Propose a blocking interface through which a process can send a message to another process. Use synchronous message passing with direct addressing.
direct addressing - přímo adresa příjemce (asymetrické) případně i odesílatele(symetrické)
MPI_SEND(buf, count, datatype, dest, tag)
IN buf initial address of send buffer (choice)
IN count number of elements in send buffer (nonnegative integer)
IN datatype datatype of each send buffer element (handle)
IN dest rank of destination (integer)
IN tag message tag (integer)
Propose a blocking interface through which a process can send a message to another process. Use asynchronous message passing with indirect addressing.
indirect addressing - příjemce i odesílatel specifikůjí adresu fronty, do které budou sypat a číst zprávy
MPI_SEND(length, msg, tag, comm)
IN comm communicator (handle)
Process Synchronization
Explain what is a race condition.
chyba při komunikaci procesů, která se projeví jen někdy – závisí na přeplánování, komunikaci může představovat i psaní nebo čtení z/do sdílené proměnné
chyba, která nastává, když dva processy přistupují současně ke sdíleným zdrojům, navíc se nemusí vždycky projevit
EDIT: Pokud výsledek závisí na načasování nebo pořadí neovlivnitelných operací/událostí. Jakýsi nedeterminismus.
Explain what is a critical section.
místo v kódu, kde může nastat race condition
EDIT: Race condition není nutně critical section. Například při logování mohu logovat události v jiném pořadí a né nutně je to pro mě critical section, pokud je append do souboru atomická operace, nemusím zamykat. Korektnější definicí je, že critical section je oblast v kódu, která nesmí být vykonávána paralelně více než jedním vláknem.
Explain the conditions under which a simple I++ code fragment on an integer variable can lead to a race condition when executed by multiple threads.
předpokládám neatomickou inkrementaci, potom lze I++ v assebleru zapsat: hodnotu načtu | přičtu 1 | zapíšu
v když dojde v místě označeném jako | k přeplánování a někdo bude pracovat s proměnnou I a změní jí, došlo k race condition
EDIT: Může to třeba být tím, že chybí volatille.
Explain the conditions under which omitting the volatile declaration on an integer variable can lead to a race condition when the variable is accessed by multiple threads.
Vynechání volatile by mohlo vadit například u stavové proměnné zámku. Pokud by se překladač, nedej Bože, rozhodl práci s ní vyoptimalizovat a nechat její hodnotu jen v registru, protože se stejně za chvíli zase bude měnit, tak zámky přestanou fungovat. Volatile tenhle druh optimalizace zakáže.
Describe the Mutual Exclusion synchronization task. Draw a Petri net illustrating the synchronization task and present an example of the task in a parallel application.
úkolem je, aby dva procesy, které vykonávají svůj kód souběžně, nevstupovaly do svých kritických sekcí
příklad: inkrementace nějakého čítače (neuvažuji atomickou inkrementaci)
vic o petriho sitich viz wiki
{kind=link}
Describe the Rendez Vous synchronization task. Draw a Petri net illustrating the synchronization task and present an example of the task in a parallel application.
úkolem je, aby se dva procesy navzájem nepředběhly, tedy aby se v určitý okamžik oba setkaly na jedom místě a teprve potom oba najednou pokračovaly v běhu
příklad: předání jednoduché proměnné mezi dvěma procesy. Randezvous dostane jako parametry tag a hodnotu. Tag je typicky adresa v paměti sdílené mezi oběma procesy. Volání randezvous způsobí uspání volajícího dokud nenastave volání randezvous se stejným tagem jiným procesem. Poté si hodnotu vymění a oba jsou probuzeni.
{kind=link}
Describe the Producer And Consumer synchronization task. Draw a Petri net illustrating the synchronization task and present an example of the task in a parallel application.
úkolem je zajistit, aby buffer, který využívají dva procesy (producent, konzument) ani nepřetekl, ani nepodtekl, tedy producent nevyrábí když nemá kam výrobek uložit a konzument nebude bouchat na dveře prázdného skladu :)
příklad: server s pevnou frontou zpráv
sit viz. treba tady
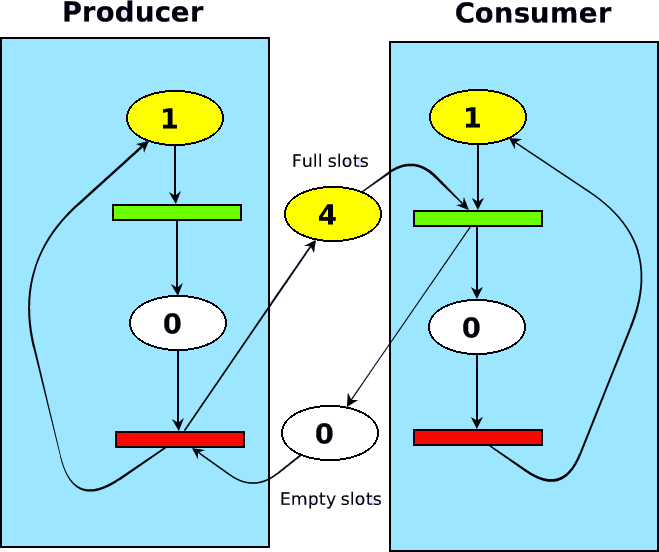{kind=link}
Describe the Readers And Writers synchronization task. Draw a Petri net illustrating the synchronization task and present an example of the task in a parallel application.
úkolem je zajistit možnost více čtenářům číst sdílenou proměnnou (paměť) a zamezit zapisovatelům, aby zapisoval v jednu chvíli více než jeden. Když se zapisuje, nikdo v tu chvíli nesmí číst.
příklad: čtení sdílené paměti
{kind=link}
{kind=link}
Describe the Dining Philosophers synchronization task. Draw a Petri net illustrating the synchronization task and present an example of the task in a parallel application.
úkolem je umožnit několika procesům exkluzivně sdílet prostředky
příklad: několik procesů se uchází o exkluzivní vlastnictví prostředků, kdo má resource, tak si jej zamkne. Chce-li stejný zdroj jiný proces, uspí se, dokud není prostředek znovu odemčen.
sit viz. na foru
{kind=link}
Explain how a deadlock can occur in the Dining Philosophers synchronization task. Propose a modification of the synchronization task that will remove the possibility of the deadlock.
například proces potřebuje ke psaní dva soubory, takových procesů je více. Jestliže si každý proces zamkne jeden soubor, nikdo nepoběží (deadlock)
rešení 1: když zamkne, nebude mít možnost psát a tak odemkne a to budou dělat všichni, nikdo zase nic nenapíše, ale systém bude maximálně vytížen. Řeší se sice deadlock, ale nastává starvation.
řešení 2: očísluju filosofy i vidličky. Px smí použít nejdříve Fx, teprve když jí vlastní, tak Fx+1. Tím se dedalock odstraní, ale je to neefektivní – všichni mohou držet jednu vidličku a dívat se na stejnou stranu, jak jeden jí a všichni čekají až položí vidličku.
řešení 3: na začátku mají všichni jednu špinavou vidličku. Když chce filosof jíst, řekne si těm vedle sebe o vidličku. Filosof vedle mu jí podá, pouze pokud jí má a je špinavá (tedy před chvílí s ní jedl), protože je slušný, cestou jí vyčistí. Kdyby měl čistou, nedá mu jí. Po dojedení jsou obě vidličky špinavé. Jedná se o velmi efektivní algoritmus!
Explain the difference between active and passive waiting. Describe when active waiting and when passive waiting is more suitable.
aktivní čekání: neustále se testuje nějaká podmínka, tím se vlastně čeká. Hodí se pro krátké časy čekání, nebo pokud není k dispozici vhodný signál na ukončení pasivního čekání. Nevýhody – žere čas CPU. Výhody: krátká doba, neobtěžuje OS, rychlejší
pasivní čekání: proces který čeká na nějakou podmínku je uspán. Probouzí se podnětem z vnějšku, tedy pokud v jiném procesu nastala sledovaná událost. Hodí se pokud se čeká dlouhý čas, tedy nehraje roli zpoždění způsobené uspáním a opětovným probuzením procesu. Musí být také k dispozici vhodný signál na ukončení pasivního čekání.
pasivní čekání lze také řešit zakázáním přerušení – nedělá se
Present a trivial solution to the mutual exclusion problem without considering liveness and fairness. Use active waiting over a shared variable. Explain the requirements that your solution has on the operations that access the shared variable.
sdílená proměnná bude obsazeno
while (obsazeno); //čekám dokud je obsazeno obsazeno=1;
//kritická sekce obsazeno=0;
na přístup ke sdílené proměnné není kladen žádný nárok. Pokud bychom chtěli a měli podporu hardware v instrukcích test and set lock, mohli bychom předcházející kód implementovat stejně, byl by funkční, ale nespravedlivý (nějaký proces by mohl setrvávat příliš dlouho ve své kritické sekci)
ze slidu:
while(true) { bIWantToEnter = true; if (!bHeWantsToEnter) break; bIWantToEnter = false;}//criticalbIWantToEnter = false;
Není to fér a nemusí se nikdo dostat k lizu, ale oproti predchozim prikladu je to bezpecny
Present a solution to the mutual exclusion problem of two processes including liveness and fairness. Use active waiting over a shared variable. Explain the requirements that your solution has on the operations that access the shared variable.
prinicp: na řadě je vždy ten druhý, když nechce, jdu já – Dekkerův algoritmus
MOJE_OBSAZENO = TRUE;while (JEHO_OBSAZENO){ if (NA_RADE != JA) { MOJE_OBSAZENO = FALSE; while (NA_RADE != JA) { }; MOJE_OBSAZENO = TRUE; }}AKCE ();NA_RADE = ON;MOJE_OBSAZENO = FALSE;
požadavky na sdílenou proměnnou: spravedlivá implementace pro N procesů musí používat minimálně N sdílených proměnných, které lze číst a zapisovat, nebo N/2 proměnných, které lze číst, zapisovat a měnit pomocí compare & swap
Peterson'ov algoritmus:
jaChcemVstúpiť = true; // deklarujem, že mám záujem vstúpiť do kritickej sekciejeNaRade = ON; // ale dám prednosť druhému procesu (ak bude chcieť)while ( onChceVstúpiť && ( jeNaRade != JA ) ) { // kým druhý proces stále javí záujem, že chce byť v kritickej sekcii // a nie som na rade ja tak čakám}// buď nastala situácia, že druhý proces dokončil svoju kritickú sekciu,// alebo ma iný proces pustil (nastavil, že na rade som ja)_KRITICKA SEKCIA_jaChcemVstúpiť = false;
Describe the priority inversion problem.
velká nevýhoda aktivního čekání – proces s nižší prioritou může zablokovat proces s vyšší prioritou (například tím, že bude pracovat se zdrojem, který proces s vyšší prioritou potřebuje). Tím se vlastně invertuje priorita těch procesů
Explain how priority inheritance can solve the priority inversion problem for simple synchronization primitives.
řešení 1: když proces začne na něco čekat, jeho priorita se propůjčí procesu vlastnícímu to, na co se čeká – funguje dobře u zámků, u synchronizačních primitiv semafor a conditional variables už ne, protože není jasné, komu by se měla priorita propůjčit, kdo to vlastně odblokuje (nevíme, kdo jako poslední vybere něco ze skladu...)
Present a formal definition of a deadlock.
2 nebo více procesů čeká na uvolnění zámku, který je zamčený jiným procesem, který také čeká na uvolnění zámku a nikdo tak nemůže pokračovat v běhu.
podmínka na níž je blokováno dva nebo více procesů, každý čeká na uvolnění zámku vlastněným tím druhým procesem
procesy musí čekat na prostředky v cyklu
procesy musí prostředky vlastnit výhradně
procesy musí být schopny přibírat si vlastnictví prostředků
prostředky nesmí být možné vrátit
Present a formal definition of starvation.
běžícímu procesu jsou neustále nedostupné potřebné prostředky, bez kterých nemůže skončit úlohu. Nastává v případě, že proces drží prostředky jinému a nechce nebo není schopen se jich vzdát. Druhý proces tedy běží, žádá o prostředky, ale doběhnout nemůže.
Present a formal definition of a wait free algorithm.
A solution to a synchronization problem is said to be wait free when every process is guaranteed to finish in a finite number of its own steps.
Wait-free algoritmus zaručuje, že všechny zúčastněné procesy skončí v konečném počtu kroků
Describe the interface of a lock and the sematics of its methods.
zámek – mutex
init_mutex – vytvoří nový zámek, vrací pointer na mutex, parametry jsou atributy (zda se při opakovaném pokusu o uzamčení vygeneruje chyba, bude se ukládat koikrát se zamknulo apod.)
destroy_mutex – zničí odemčený zámek, parametrem je pointer na zámek
lock_mutex – uzamkce mutex, paramterem je pointer na mutex
unock_mutex – odemkne mutex, paramterem je pointer na mutex
trylock – vrací true, pokud je možné zámek uzamnknout, parametrem je pointer na mutex
void mutex_init (struct mutex * mtx) Funkce inicializuje mutex do stavu odemceno.
void mutex_destroy (struct mutex * mtx) Funkce provede uklid ridici struktury mutexu. Pokud je rusen mutex,
na kterem jsou jeste zablokovana nejaka vlakna, funkce vyvola panic.
void mutex_lock (struct mutex * mtx)
int mutex_lock_timeout (struct mutex * mtx, const unsigned int usec) Funkce se pokusi zamknout mutex, pokud to neni mozne, zablokuje
vlakno na mutexu. Varianta _timeout ceka na zamknuti mutexu nejdele usec mikrosekund.
Pokud se behem teto doby podari mutex zamknout, vraci EOK, jinak ETIMEDOUT. Pokud je casovy limit 0, k zablokovani vlakna nedochazi.
void mutex_unlock (struct mutex * mtx) Funkce odemkne zadany mutex a vzbudi vlakna, ktera byla zablokovana
pri zamykani mutexu. Pokud je symbol DEBUG_MUTEX >= 1, bude implementace mutexu hlidat, zda je odemykan vlaknem, ktere ho puvodne
zamknulo. Pokud bude mutex odemykat jine vlakno, vyvola panic.
Describe the interface of a read-write lock and the sematics of its methods.
rwlock_init – inicializuje počet čtenářů, vytváří mutex a vrací pointer na rwlock
rwlock_write_lock – vstup písaře do kritické sekce, uzamčeno pro zápis
rwlock_read_lock – inkrementuje počet čtenářů, vstup do kritické sekce
rwlock_write_unlock – oznámení ukončení psaní
rwlock_read_unlock – odchod jednoho čtenáře z kritické sekce
možné ještě trylock a lock_timeout
void rwlock_init (struct rwlock * rwl)
Funkce inicializuje ridici strukturu r/w zamku do stavu odemceno.
void rwlock_destroy(struct rwlock * rwl)
Funkce provede uklid ridici struktury zamku. Pokud je rusen zamek, na kterem jsou jeste zablokovana nejaka vlakna, funkce vyvola panic.
void rwlock_read_lock (struct rwlock * rwl)
void rwlock_write_lock (struct rwlock * rwl)
int rwlock_read_lock_timeout (struct rwlock * rwl, const unsigned int usec)
int rwlock_write_lock_timeout (struct rwlock * rwl, const unsigned int usec)
Funkce se pokusi zamknout zamek v pozadovanem rezimu, pokud to neni mozne, zablokuje volajici vlakno na zamku.
Varianta _timeout ceka na zamknuti zamku nejdele usec mikrosekund. Pokud se behem teto doby podari zamek zamknout, vraci EOK, jinak
ETIMEDOUT. Pokud je casovy limit 0, k zablokovani vlakna nedochazi.
void rwlock_write_unlock (struct rwlock * rwl)
void rwlock_read_unlock (struct rwlock * rwl) Funkce odemkne zamek a odblokuje vlakna zablokovana na zamku.
Explain when a lock is a spin lock.
zámek čeká na uvolnění aktivně, spinning označuje opakované testování přístupu
Explain when a lock is a recursive lock.
zámek lze zamknout vícekrát stejným threadem – vlastníkem, odemknout se musí tolikrát, kolikrát byl zamknut
Explain why Windows offer Mutex and CriticalSection as two implementations of a lock.
critical sections ve Windows NT si pamatují vlastníka, je možné je zamknout jedním threadm několikrát, jsou poměrně rychlé, ale fungují pouze v rámci jednoho procesu
mutexy – pro synchronizaci mezi procesy – mají také vlastníka a lock count
Implement a solution for the mutual exclusion synchronization problem using locks.
oba sdílí jeden zámek, před vstupem do kritické sekce proces zámek zamkne, pro ukončení kritické sekce se zámek zase odemkne
Describe the interface of a semaphore and the sematics of its methods.
sem_init – vrací pointer na nově vytvořený semafor s hodnotou danou parametrem
sem_down – sníží atomicky hodnotu semaforu, pokud už byla nula, je proces který semafor volal uspán a čeká na semaforu (vyčerpal jsem kvótu danou semaforem)
sem_up – je-li na semaforu nějaký čekající proces je odblokován, jinak se zvyšuje hodnota semaforu
sem_destroy – zničí semafor, je možné různé chování v případě, že na semaforu někdo čeká (všichni se probudí, vyhodí se chyba...)
sem_trydown – vrací true pokud je možné semafor snížit
sem_down_timeout – po určitou dobu se bude pokoušet semafor snížit
semafor (s casovym limitem)
void sem_init (struct semaphore * sem, const int value)
Funkce inicializuje semafor a nastavi ho na zadanou hodnotu.
void sem_destroy (struct semaphore * sem)
Funkce provede uklid ridici struktury semaforu. Pokud je rusen semafor, na kterem jsou jeste zablokovany nejake thready, funkce
vyvola panic.
int sem_get_value (struct semaphore * sem)
Funkce vrati hodnotu semaforu >= 0.
void sem_up (struct semaphore * sem)
Funkce inkrementuje hodnotu semaforu a pripadne odblokuje jedno z vlaken na nem zablokovanych.
void sem_down (struct semaphore * sem)
void sem_down_timeout (struct semaphore * sem, const unsigned int usec)
Funkce dekrementuje hodnotu semaforu pokud je to mozne, jinak vlakno na semaforu zablokuje.
Varianta _timeout ceka na dekrementovani hodnoty semaforu nejdele usec mikrosekund. Pokud se behem teto doby podari semafor dekrementovat,
vraci EOK, jinak ETIMEDOUT. Pokud je casovy limit 0, k zablokovani vlakna nedochazi.
Implement a solution for the producer and consumer synchronization problem over a cyclic buffer using semaphores.
semafory budou tři – mutex, empty a full
semaphore mutex = 1; //slouží k atomickému přístupu do skladusemaphore empty = N;semaphore full = 0;PRODUCER:produce_item(&item)down(&empty)down(&mutex)enter_item(item)up(&mutex)up(&full)CONSUMER:down(full)down(mutex)remove_item(&item)up(&mutex)up(&empty)consume_item(item)
Describe the interface of a condition variable and the sematics of its methods.
pro potřeby čekání na nějakou složitější podmínku, než jen například plný X prázdný buffer
cond_init – inicializace podmíněné proměnné, vrací pointer na condvar
cond_signal – pokud někdo spí na podmíněné proměnné, je jeden proces probuzen
cond_broadcast – všechny procesy spící na podmíněné proměnné jsou probuzeny
cond_wait – volající proces se na podmíněné proměnné uspí
cond_timedwait – pokud před koncem doby nebude podmínka splněna, proces se uspí
cond_destroy
void cond_init (struct cond * cvar) Funkce inicializuje ridici strukturu condition variable.
void cond_destroy (struct cond * cvar) Funkce provede uklid struktury condition variable. Pokud je rusena
condition variable, na ktere jsou jeste zablokovany nejake thready, funkce vyvola panic.
void cond_signal (struct cond * cvar)
void cond_broadcast (struct cond * cvar)
Funkce odblokuje jedno resp. vsechna vlakna cekajici na condition variable.
void cond_wait (struct cond * cvar, struct * mtx)
int cond_wait_timeout (struct cond * cvar, struct mutex * mtx, const unsigned int usec)
Funkce atomicky odemkne mutex a zablokuje volajici vlakno na condition variable. Po odblokovani opet zamkne mutex a vrati
rizeni volajicimu. (mutex chrání testování podmínky)
Varianta _timeout zablokuje vlakno nejdele na usec mikrosekund, resp. na dobu odpovidajici limitu a dobu nutnou k opetovnemu zamceni mutexu.
Pokud behem teto doby dojde k odblokovani vlakna, vraci EOK, jinak ETIMEDOUT. Pokud je casovy limit 0, k zablokovani vlakna nedochazi,
ale pred opetovnym zamcenim mutexu se vlakno jednou vzda procesoru.
Explain what is a monitor as a synchronization tool and what methods it provides.
skládá se z procedur schopných pracovat se sdílenou proměnnou, mutexu, proměnnou asociovanou se zdrojem (kvůli kterému se synchronizuje) a invariantu, který definuje podmínku potřebnou pro vyhnutí se race condition
voláním procedury se zamyká zámek, který si proces ponechává do doby, než procedura naskončí, nebo se čeká na platnost podmínky
každá procedura garantuje, že invariant je v době jejího skončení platný, tím pádem žádný proces nemůže převzít zdroj ve stavu, kdy by mohlo nastat race condition
Management Among Processes
Internal fragmentation leads to poor utilization of memory that is marked as used by the operating system. Explain how internal fragmentation occurs and how it can be dealt with.
Interní fragmentace nastává, pokud uživatel dostane větší blok paměti, než si objednal / využívá. To se stává například u heap alokátorů, které umí přidělovat bloky jen o velikostech v násobcích nějaké konstanty. Například buddy systém, který umí jen mocniny dvojky může docílit toho, že proces chce 17B paměti, ale dostane 32B, tedy skoro 50% interní fragmentace. Řešení zas tak moc asi není, jenom přidělovat bloky co nejbližších velikostí jako požadované. Uživatel typicky neví, že má víc paměti, než chtěl, tak s tím moc neudělá.
External fragmentation leads to poor utilization of memory that is marked as free by the operating system. Explain how external fragmentation occurs and how it can be dealt with.
Externí fragmentace spočívá v tom, že v paměti jsou mezi velkými bloky roztroušeny malé, které jsou ale tak malé, že je nikdo nechce. V součtu má tedy systém stále hafo volné paměti, ta je ale rozdrobena do nepoužitelných kousků. Stává se to například zase u těch heap alokátorů, když se hodně alokuje / uvolňuje. Řešení je například bloky setřepat a tím volné místo spojit, to ale jde jenom tehdy, pokud v kódu nejsou absolutní adresy.
Explain how memory virtualization through paging works and what kind of hardware and operating system support it requires.
Procesy nepracují přímo s fyzickou pamětí počítače. Místo toho se jejich virtuální adresní prostor mapuje na fyzický. Pro tyto účely jsou jak virtuální tak fyzický prostor rozděleny do bloků relativně malé pevné velikosti (stránek). Fyzické i virtuální stránky jsou stejně velké. Když proces přistupuje na nějakou adresu, tak ta se nejprve přeloží na fyzickou a s tou se teprve pracuje. Problém je právě v tom překladu a na to je potřeba podpora HW a OS. HW musí vědět, že adresy jsou virtuální a musí mít nějakou jednotku, která se stará o překlady. OS musí dát HW k dispozici data k překladu do stránkovacích tabulek. Musí tyto tabulky vyplňovat a udržovat, přepínat je při přepnutí paměťového kontextu a případně taky stránky swapovat.
At the level of individual address bits and entry flags, describe the process of obtaining physical address from virtual address on a processor that only has the Translation Lookaside Buffer. Explain the role of the operating system in this process.
Při překladu adresy se vezme počáteční úsek bitů adresy a zkusí se vyhledat v TLB. Délka tohoto úseku závisí na velikosti stránky a samozřejmě na délce adresy (při 32bit adresách, 4kB stránkách je to 20 bitů). Pokud se mapování v TLB najde, tak se k číslu rámce z TLB přičte zbytek bitů adresy, které tvoří offset do stránky a to dá výslednou fyzickou adresu.
Bity, které typicky ještě ovlivňují vyhledávání: Global bit - mapování je globální, platí ve všech adresních prostorech
ASID - Address Space Identifier, pokud není nastaven global bit, při hledání mapování se porovnává ještě identifikátor aktuálního adresního prostoru Valid bit - Indikuje, zda je mapování platné
Present bit - Indikuje, zda je stránka v paměti, nebo je odswapovaná Role operačního systému je udržovat TLB platnou a naplňovat jí, pokud v TLB není nalezeno mapování.
To kolika stupňové je stránkování a jak probíhá překlad řeší na mipsu operační systém, na některých jiných architekturách existuje určitá hw podpora.
At the level of individual address bits and entry flags, describe the process of obtaining physical address from virtual address on a processor that supports multilevel page tables. Explain the role of an operating system in this process.
Při n úrovňových stránkovacích tabulkách se virtuální adresa rozdělí na n+1 úseků, z nichž prvních n (od nejvyšších řádů) slouží jako indexy do stránkovacích tabulek příslušné úrovně a poslední úsek je opět offset do stránky. První úsek slouží jako index do adresáře stránkovacích tabulek, který jediný musí být vždy namapovaný. Flagy jsou podobné jako u TLB. Role systému je vyplňování a udržování stránkovacích tabulek a taky přepnutí adresáře stránek při přepínání paměťového kontextu.
Explain the relation between the page size and the size of the information describing the mapping of virtual addresses to physical memory and list the advantages and disadvantages associated with using smaller and larger page sizes.
velikost stránky je rozhodující pro velikost tabulky pro překlad
pro adresový prostor 32 bitů určuje 12 bitů offset do stránky, tedy stránka bude mít 4KB. Zbývá 20 bitů na adresu stránky, tedy 2^20 položek. Bude-li mít položka velikost 4 byte, potřebujeme tabulku 4MB
velké stránky nám ukrojí moc velkou část na offset, naopak malé stránky neúnosně zvětšují překladovou tabulku
EDIT: A v čem nám vadí mít ukrojenou velkou část na offset? 16KiB page = 14 offset -> 9, 9 indexy do tabulek. Bude fungovat v pohodě. Navíc se nám vejde do jedné stránky 4x tolik, takže možná i menší počet výpadků v TLB. Ten hlavní problém tohohle použití je ten, že hrozí větší interní fragmentace. Sekundární je ten, že ta velikost stránky je dneska zadrátovaná na X místech v os a blbě se to mění. A ta formulace toho, že malé stránky neúnosně zvětšují překladovou tabulku by chtěla upřesnit. Oni především mohou vynucovat větší počet úrovní. Což prodlužuje page walking. Obskurní příklad: 1KiB page = 10 offset, 256 záznamů na tabulku => 8 bitu na index do tabulky -> 6,8,8 indexy a 10 offset. Zbytečně jsme si vynutili další úroveň.
List the advantages and disadvantages of using multilevel page table as a data structure for storing the mapping of virtual to physical memory.
výhody – není třeba rezervovat prostoru pro tabulku stránek celé virtuální paměti, stačí pro použitou část, části tabulky mohou být stránkovány, tabulky v první úrovni mohou mít záznam „not present“, čímž se šetří místo pro tabulky na nižších úrovních, na které by ten záznam ukazoval
nevýhody – zvyšuje se počet přístupů do paměti, zpomaluje procesor
List the advantages and disadvantages of inverse page table as a data structure for storing the mapping of virtual to physical memory.
Inverted hash tables - mapuje fyzické stránky na virtuální, něco na styl asociativní paměti, pro překlad virt->phy hašování
výhody – je to rychlé, velikost tabulky závisí na velikosti fyzické, nikoli virtuální paměti
nevýhody – špatně se prohledávají – hašováním, řešit kolize by bylo nákladné a tak je třeba ještě dodatečných datových struktrur, které využívá OS. Ztěžuje sdílení paměti.
Explain what a Translation Lookaside Buffer is used for.
cache pro překlad virtuálních na fyzické adresy, první místo, kam se procesor dívá, zdali existuje mapování. Pokud ne, zkoumá překladové tabulky nebo dráždí OS
Describe the hardware realization of a Translation Lookaside Buffer and explain the principle and advantages of limited associativity.
položky TLB jsou rozděleny do množin (bank) s velikostí N, kde N udává číslo asociativity. Samotné asociativní prohledávání spočívá v HW realizaci pomocí komparátorů, paměť je tedy asociativní pouze v rámci každé množiny - limited cache associativity
plnně asociatvní paměti jsou drahé, protože jdou špatně vyrobit (fyzika, přetížení obvodů)
výhoda – je to levnější než fully associativity
Co se tím vlastně myslí:
mám nějakou cache, v ní 50 položek a potřebuju najít rychle položku podle klíče
mám 5000 komparátorů, kterými postupně ten klíč prochází -> najdu danou položku
komparátory jsou drahé, tak si to výrobci HW rozdělí
prohledám prvních 10 (30 komparátorů)
prohledám dalších 10 (30 komparátorů)
...
Výhody: snížení počtu komparátorů -> levnější, nevýhody pomalejší
EDIT: Pardon, ale tohle je totální nesmysl. Neprohledávám postupně jednu množinu za druhou, to by pak trvalo O(|TLB size|/|N|). V reálu to trvá O(1). Funguje to tak, že vezmu adresu a určím v jaké bance hledat (třeba modulo počtem bank). A v té bance potom spustím hledání s plnou asociativitou. Tzn. je to kombinace: indexace + plně asociativní search. Nevýhody jsou takové, že pokud mám n-asociativní TLB. Tak riskuji, že mi záznamy budou padat často do jedné banky, která je velká n a bude se to tam vyhazovat mezi sebou. Na druhou stranu ji mohu mít větší, než kdyby byla plně asociativní. Plně asociativní má třeba MIPS. V podstatě je to stejná anabáze jako s asociativitou u standardní cache. A poslední věc. TLB mohou mít i několik úrovní. Takže teď třeba střílím, ale první by mohla být malá a plně asociativní, druhá třeba n-cestně a poslední jen indexovací.
How does the switching of process context influence the contents of the Translation Lookaside Buffer ? Describe ways to minimize the influence.
při přepnutí kontextu je třeba invalidovat i TLB (instrukce TLB_INVALIDATE) - většinou se z tabulek vše vyhodí a poté se znovu naplní
na multiprocesorech má každý CPU svou TLB, musí se vyprázdnit všechny (musí se dát vědět všem virtuálním adresovým prostorům, aby nikde nezůstaly neplatné virtuální adresy)
lze zlepšit tagovanim stranek tak, že jsou některé namapovány ve všech adresních prostorech a z TLB se nevyhazují
Tohle je celkem hloupost.
Pří context switchi není potřeba flushovat TLB na všech procesorech. Mapovaní adress spacu danýho procesu se nemění (nevolá se nějaký vma_alloc, vma_free atd.) -> tj. pokud mi tam běží dvě vlákna na dvou procesorech se stejným virt. adress spacem, tak bohatě stačí invalidovat tlb vlákna, co se přepíná.
Zlepšení :
pokud je v HW věc jako na mipsu ASID, tak tak se zaznamy při přepnutí kontextu nemusí invalidovat, pokud nemáme pro dva různé procesy stejný ASID
pokud thread co běží a thread, co bude běžet, mají stejný adress space, tak se tlb vůbec nemusí invalidovat
z toho pak vychází odvážná myšlenka - snažit se, aby thready, které pouštíme na jednom procesoru byly asociovány s co nejmenším počtem různých adress spaců
Provide at least two criteria that can be used to evaluate the performance of a page replacement algorithm.
kolik informací je potřeba skladovat, aby algoritmus vůbec mohl rozumně běžet
počty výpadků stránek za běhu aplikace
rychlost algoritmu – dlouhé hledání volných stránek je mi na tužku
Já bych ještě dodal zátěž na pozadí. Příklad: při přeplánování musím projít celé mapování a podle accessed, dirty bitů a na základě dat s historie si spočítat histogramy, pstní koláčky a počasí na příští týden :)
Explain the principle of the First In First Out page replacement algorithm and evaluate the feasibility of its implementation on contemporary hardware along with its advantages and disadvantages.
princip: vyhodí se ta stránka, která přišla před nejdelší dobou, je nejdéle v paměti
realizace: velmi dobrá, drží se pointer na nejstarší stránku a po jejím vyhození se posune
výhody: je rychlý, snadno realizovatelný
nevýhody: Beladyho anomálie (012301401234), nezohledňuje využívání stránek procesem – například stránka s velice často využívanými proměnnými bude určitě vyhozena a bude se muset znovu zavádět
Explain the principle of the Not Recently Used page replacement algorithm and evaluate the feasibility of its implementation on contemporary hardware along with its advantages and disadvantages.
princip: na kterou stránku se nikdo dlouho nedíval ani do ní nepsal, tu asi nikdo nebude potřebovat i v nejbližsí době – princip lokality, algoritmus předpokládá, že referncovaná stránka je důležitější než změněná
realizace: množiny stránek rozdělené do čtyř kategorií podle nastavených Access a Dirty bitů – (A0D0, A0D1, A1D0, A1D1), vyhazují se vždy stránky z nejnižší kategorie. Podmínka – HW periodicky schazuje Access bit, například po určitém počtu přerušení od timeru, A i D bity se nahazují/shazují hardwarově, na čtyři skupiny si stránky dělí OS
výhody :
asi žádné velké, strategie se moc nepoužívá (nejspíš kvůli nutnosti neustále měnit bity podle signálu z časovače -> příliš velká režie)
jinak nejspíš se tím dá zajistit statisticky nižší pravděpodobnost výpadku stránky než při FIFO
Explain the principle of the Least Recently Used page replacement algorithm and evaluate the feasibility of its implementation on contemporary hardware along with its advantages and disadvantages.
princip: stránky používané před krátkým okamžikem budou asi opět brzy použity, budeme si tedy pamatovat dobu, kdy byly stránky použity naposledy a vyhazujeme ty s největší hodnotou čítače – nejdéle nepřistoupené stránky se vyhazují
realizace: v HW – 64-bitový čítač inkrementovaný po každé instrukci, moc se nepoužívá, v SW – linked list (nepoužívá se, moc velká režie), další možnost – matice n krát n podle počtu rámců, při použití rámce k nastavit řádek k na samé jedničky a vynulovat sloupec k. Při výpadku se pak vybírá rámec s nejnižší binární hodnotou.
výhody: dá se statisticky zpracovat, dokázalo se, že LRU nezpůsobí nikdy víc než n-krát víc výpadků oproti optimálnímu algoritmu
nevýhody: známé případy, kdy algoritmus selhává – například aplikace, která bude procházet N+1 stránek způsobí výpadek při každém přístupu
Explain the principle of the Least Frequently Used page replacement algorithm and evaluate the feasibility of its implementation on contemporary hardware along with its advantages and disadvantages.
princip: stránka s nejmenší frekvencí přístupů za poslední dobu se vyhodí
realizace: v současném HW je velmi bídná
nevýhody: informace o počtu přístupů za časovou jednotu je stěží k dispozici, používají se odhady a aproximace, špatné chování algoritmu při změně vytížení stránek (například po startu systému kdy už startovací stránky nebudou potřeba, ale nevyhazují se, protože byly intenzivně využívány)
výhody: samy o sobě nejsou, strategie různých algoritmů se musí kombinovat
Explain what is a working set of a process.
množina stránek ve fyzické paměti, které patří určitému procesu, mění se s během procesu
pokud je working set příliš velký, může běžet zároveň méně procesů, když příliš malý, musí se častěji spouštět swapování
Explain what is a locality of reference and how it can be exploited to design or enhance a page replacement algorithm.
předpokládá se, že se program v určitých částech bude stále „motat na místě jako vítr v bedně“, tedy je vhodné nejčastěji přistupované stránky za poslední dobu nebo naposledy navštěvované stránky nevyhazovat
souvisí s cachováním i s tlb
Explain what is thrashing and what causes it. Describe what can the operating system do to prevent thrashing and how can the system detect it.
v případě že se working sets běžících procesů nevejdou do paměti, jedna stránka se vyhodí a začne se swapovat, jenže proces jemuž byla stránka vyhozena chce běžet a tak se začne swapovat stránka zpátky a tak pořád dokolečka – nakonec se jen swapuje a neudělá se nic
řešení: vyswapuje se celý jeden proces (obětní beránek) a nepoběží vůbec, zvýšení RAM
detekce: ponechá se rezerva, přes kterou už nebudu povolovat ukládání do paměti. Jakmile se překročí, začne se swapovat „dopředu“
Explain the concept of memory mapped files.
díky virtuální paměti máme možnost namapovat velký externí soubor do paměti a přistupovat k němu, jako by byl v paměti celý – urychluje to práci se soubory, protože se nepřistupuje k externím pamětem
podstatné je, že pro práci s MMF není třeba volat systém, ale používají se běžné instrukce pro práci s pamětí
Explain the priciple of the copy-on-write mechanism and provide an example of its application in an operating system.
když více procesů chce sdílet stejná data (mapování souboru s flagem private například), OS je do paměti namapuje pouze jednou a označí je read-only a jakmile chce na stránku někdo psát, vyvolá se vyjímka, OS se ujme řízení a stránka je okopírována jinam do paměti, kde se do ní zapíše)
používá se to například při sdílení stringů - jakmile pouze čteme stačí namapovat sdílenou paměť, jakmile chceme měnit, budeme to muset zkopírovat
Allocation Within A Process
Identify where the following function relies on the virtual address space to store executable code, static data, heap and stack.
<strong>void *SafeAlloc (size_t iSize)</strong> // funkce = staticka data - v kodu, parametry na stacku
<strong>{</strong> <strong> void *pResult = malloc (iSize);</strong> // dynamicky alokovane veci na heapu, lokalni prom. na stacku
<strong> if (pResult == NULL)</strong> <strong> {</strong>
<strong> printf ("Failed to allocate %z bytes.\n", iSize);</strong> // static. data (string) v kodu <strong> exit (ENOMEM);</strong>
<strong> }</strong> <strong> return (pResult);</strong> // vysledek funkce na stack
<strong>}</strong>
List four distinct types of content that reside in a virtual address space of a typical process .
executable code – strojový kód v instrukcích procesoru
static data – staticky alokované proměnné
heap – halda, dynamicky alokovaná data
stack – zásobník, pro ukládání návratových adres, argumentů procedur, registrů a lokálně alokovaných dat
a) Executable code.
contains the machine code instructions to be executed by the processor. It is often write protected and shared among processes that use the same main program or the same shared libraries.
b) Static data. contains the statically allocated variables to be used by the process.
c) Heap. contains the dynamically allocated variables to be used by the process.
d) Stack. contains the stack to be used by the process for storing items such as return addresses, procedure arguments, temporarily saved registers or locally allocated variables.
Kod a static data su nemenne a ich poloha je determinovana compilerom. Stack a heap su dynamicke a rastu oproti sebe (stack dole a heap smerom hore).
pozn. Vsechno jde menit, zalezi kam se zapise.
Jinak staticka data jsou i globalni promene, takze se meni pomerne casto. Stack a heap rostou tim smerem, jak si to porgramator naprogramuje...
Explain the advantages of segmentation over flat virtual memory address space.
není třeba řešit rozložení heap X zásobník a jiné bloky paměti
to co je důležíté je, že každý blok paměti (executable code, heap, stack..) bude jeden segmet
to nám umožní i efektivně zjišťovat, zda například program nesahá „nad“ zásobník, při porovnávání adresy se segment registrem by se to zjistilo a proces který tak učinil by byl zastřelen
No page faults -- whole segment is present at once -- only access violations need to be trapped
No internal fragmentation -- segment size is customized to each process
Easier to implement virtual OS
per segment protection (ochrana pameti)
snadnejsi sdileni dat (sdilim funkci/ ne naky stranky)
virtual space
EDIT: Otázkou je porovnání proti ploché virtuální paměti. Ta také zaručuje separaci a bezpečnost. Heap vs. zásobník se řešit ani moc nemusí, když jsou proti sobě, tak prostě jakmile se potkají došla paměť. V tom segmentace nepomůže. Hlavní přínos segmentace oproti ploché virtuální paměti přichází ve chvíli, kdy mám více threadů v jednom adresním prostoru. Pak nelze moc hezky umístit zásobníky. Segmentace mi umožní je snadno přemisťovat na základě toho, jak rostou. A další výhodou je snadná realokace kódu. A pokud mám segmentaci over VAS, pak mám také výpadky stránek a nic mi to neusnadňuje, což dnes typicky mám. Záleží, jak byla otázka myšlena.
Explain why random placement of allocated blocks in the virtual address space of a process can contribute to improved security.
útočník nemůže dělat žádné závěry o tom, kde bude blok v paměti uložen, a to mu znesnadňuje „buffer overflow attack“
útok spočívá v zápisu hodnoty delší než je alokovaná vstupní proměnná, čímž se přepíše jiná hodnota na zásobníku, která leží pod vstupní proměnnou. Při návratu z procedure je návratový kód vyzvedávaný ze zásobníku jiný a může směřovat na sadu škodlivých, útočníkem podsunutýc instrukcí
Prevencia proti exploitom - napr buffer overflow. S kazdym spustenim programu ho rozhadze po pamati randomne, teda sa neda predpokladat ze bude napr. buffer overflow fungovat.
Explain what the processor stack is used for with typical compiled procedural programming languages.
používá se pro uschovávání návratových adres, argumentů procedur a funkcí, dočasně uložených registrů procesoru a lokálně alokovaných proměnných
k přístupu k zásobníku se používá stack pointer, regist obsažený v CPU
The process stack is typically used for return addresses, procedure arguments, temporarily saved registers and locally allocated variables. The processor typically contains a register that points to the top of the stack. This register is called the stack pointer and is implicitly used by machine code instructions that call a procedure, return from a procedure, store a data item on the stack and fetch a data item from the stack.
For a contemporary processor, explain how the same machine instructions with the same arguments can access local variables and arguments of a procedure regardless of their absolute address in the virtual address space. Explain why this is important.
příklad na Intel IA32
instrukce push and pop – při volání procedury se sníží ESP register o velikost návratové adresy a ta se uloží
k adresování lokálních proměnnch a argumentů se využívá EBP – base pointer. Ten je po volání procedury uložen na zásobník a zároveň je do EBP uložena hodnota ESP
na zásobníku se vyhradí místo pro proměnné tím, že se k SP přičte tolik byte, kolik lokální proměnné zabírají. Proměnné se uloží nad ESP, argumenty se uloží pod ESP
stack roste od větších k menším adresám, to má tu výhodu, že může být umístěn na konci paměťového prostoru. Nepoužívají se absolutní adresy do VAP, ale pouze relativní vzhledem EBP
The use of stack for procedure arguments and locally allocated variables relies on the fact that the arguments and the variables reside in a constant position relative to the top of the stack. The processor typically allows addressing data relative to the top of the stack, making it possible to use the same machine code instructions to access the procedure arguments and the locally allocated variables regardless on their absolute addresses in the virtual address space, as long as their addresses relative to the top of the stack do not change.
Importance: shared libraries.
Explain what is the function of a heap allocator.
určuje kam se umístí dynamicky alokovaná proměnná
pracuje nad strukturou bloků s informacemi, které kusy haldy jsou prázdné a které volnépožadavky na alokátor – rychlost, malá režie, úspornost, a dodatečné fíčury (rezise, garbage collector, debugging, zero-fill, align)
The process heap is used for dynamically allocated variables. The heap is stored in one or several continuous blocks of memory within the virtual address space. These blocks include a data structure used to keep track of what parts of the blocks are used and what parts of the blocks are free. This data structure is managed by the heap allocator of the process. In a sense, the heap allocator duplicates the function of the virtual memory manager, for they are both responsible for keeping track of blocks of memory. Typically, however, the blocks managed by the heap allocator are many, small, short-lived and aligned on cache boundaries, while the blocks managed by the virtual memory manager are few, large, long-lived and aligned on page boundaries. This distinction makes it possible to design the heap allocator so that it is better suited for managing blocks containing dynamically allocated variables than the virtual memory manager.
Usually, the heap allocator resides within a shared library used by the processes of the operating system. The kernel of the operating system has a separate heap allocator.
Explain why the implementation of the heap allocator for user processes usually resides in user space rather than kernel space.
Od heap alokátoru se typicky očekává rychlost a volá se často, proto by bylo neefektivní na každé jeho zavolání ještě přikládat celou režii kolem syscallů. To je podle mne hlavní důvod. Ještě bych dodal jeden menší důvod a to sice ten, že pokud si proces tu paměť poškodí, tak hrozí riziko, že poškodí i struktury toho mallocu a pokud by byl ten malloc puštěn jako privilegovaný, tak by mohl shodit kernel přístupem na špatnou adresu. Což by vyžadovalo neustále detekce toho, zda je heap konzistentní a pointery v interních strukturách nemíří ven, což se využívá asi spíše jen v debug módu, protože za runtimu to žere čas.
Design an interface of a heap allocator.
void *malloc(size_t size);
void free(void *pointer);
void * malloc(size_t size);
void free(void *ptr); size_t get_size(void *ptr);
Explain the problems a heap allocator implementation must solve on multiprocessor hardware and sketch appropriate solutions.
kdyby sloužil pro všechny procesory naráz, stal byse heap allocator úzkým hrdlem – při hledání volného místa by brzdil ostatní procesory
řešením je hierarchický alokátor, který si udržuje „local free block pools“, tedy nabídku pro jednotlivé procesory s tím, že když na vrcholu hierarchie dojde místo, přelévají se z local do global free block poolu
Multiprocesorové systémy mají u alokátoru podobné problémy jako plánovace nad ready frontou, tedy prílią mnoho soubehu je zpomaluje. Proto se delají hierarchické alokátory, local free block pools, které se v prípade potreby prelévají do global free block poolu.
Explain the rationale behind the Buddy Allocator and describe the function of the allocation algorithm.
princip je půlení paměti – někdo požaduje blok paměť, kterou půlíme do té doby, než nemáme blok minimální možné velikosti, nebo velikosti větší než požadovaná paměť
pro volné X obsazené bloky máme bitmapu – pro každou možnou velikost bloku jednu bitmapu, alternativní řešení je v hlavičce každého bloku uchovávat infromace o blocích a seznamech volných bloků
při odalokování bloku se uvolněný se sousedním spojí (pokud je soused prázdný) a budou se spojovat dokud neuvolní celou paměť, nebo nenarazí na obsazený blok
výhody – je jasně daná velikost bloků, přijatelná doba na alokování – dealokoání paměti
nevýhoda – vysoká fragmentace, je daná pevnou sadou délek bloků
Pamět rozdělena na bloky o velikosti 2n. Bloky stejné velikosti v seznamu. Při přidělení zaokrouhlit na nejbliľąí 2n. Pokud není volný, rozątípnou se větąí bloky na přísluąné menąí velikosti. Při uvolnění paměti se slučují sousední bloky (buddy).
Klady - Rozdelenie aj zlucovanie rychle. Moze byt pouzity binary tree pre pamatanie si volnych a plnych blokov. Zapory - internal (chcem 66kb - da mi 128kb) a external fragmentation (vela 64kb blokov roztrusenych ale ziadny 128kb blok).
Explain the rationale behind the Slab Allocator and describe the function of the allocation algorithm.
prinicp: nejčastěji se alokují malá data, trik je v tom, že nejčastěji používané objekty jsou již připravené na stránkách, to snižuje režii odstraněním alokace těchto objektů, jedna stránka tak obsahuje řadu objektů, čímž se šetří paměť a snižuje se interní fragmentace
použití: unix
terminologie: slab je kontejner na objekty a je tvořen několika stránkami, cache se skládají ze slabů, objekt je nejmenší jednotka alokace, nachází se ve slabu
EDIT: Lidsky řečeno, tak jak to mám v poznámkách. Pamatuje si objekty na kterých byly zavolány destruktory. A pokud budeme chtít new objekt stejného typu, tak nám ho rovnou vrátí, bez alokace a bez volání konstruktoru. Musí ale zajistit, že objekt byl ve stejném stavu jako po zavolání konstruktoru. Tohle mi přijde divné, ale nějak tak to popisoval.
Describe what a heap allocator can do to reduce the overhead of the virtual memory manager.
je výhodné, aby alokátor udržoval lokalitu, tedy aby nedávno alokované bloky umisťoval blízko sebe, protože budou pravděpodobně používány společně
v případě přestránkování tedy mechanismus virtualizace nebude muset vyhazovat hodně stránek
alokátor nejprve zkouší exact fit, v případě že to není možné zkusí rozdělit volný blok, ze kterého se přidělovalo naposledy
tj. lepší mít naalokovaný bloky co nejvíc namačkaný u sebe, než roztroušený po paměti
Statistiky overheadu pro konkrétní aplikace uvádejí 4% pro best fist, 7% pro first fit na FIFO seznamu volných bloku, 50% pro first fit na LIFO seznamu volných bloku, 60% pro buddy system.
Explain the function of a garbage collector.
garbage collector sám uvolňuje paměť, kterou už žádný proces nevyužívá
vyhazuje z paměti ty bloky, na které už nemáme ukazatel, ne ty bloky, které už nepotřebujeme
A garbage collector replaces the explicit freeing of blocks with an automatic freeing of blocks that are no longer used. A garbage collector needs to recognize when a block on the heap is no longer used.
A garbage collectors determines whether a block is no longer used by determining whether it is reachable, that is, whether a process can follow a chain of references from statically or locally allocated variables, called roots, to reach the block.
Define precisely the conditions under which a memory block can be freed by a reference tracing garbage collector.
dosažitelnost – pokud proces může sledovat retěz referení od staticky nebo lokálně alokovaných proměnných, tzv. roots tak, že dojde ke každému bloku (jsou dosažitelné referencí z call stacku, nebo globálních proměnných); funguje tranzitivita
What is reachable object:
A distinguished set of objects are assumed to be reachable -- these are known as the roots. Typically, these include all the objects referenced from anywhere in the call stack (that is, all local variables and parameters in the functions currently being invoked), and any global variables.
Anything referenced from a reachable object is itself reachable. This is referred to as transitivity.
Predpokladam ze vsetko non-reachable moze ist do /dev/null
Describe the algorithm of a copying garbage collector.
paměť je rozdělena na dvě části, při alokování se zaplňuje jen jedna (from space a to space), jakmile paměť dojde, jsou všechny dosažitelné proměnné kopírovány do druhé části, takto se neustále přelévá
nevýhoda je potřeba velké souvislé části paměti ve chvíli, kdy garbage collector pracuje
Vsetko sa alokuje v oblasti 1. Ked sa zaplni, tzn. "root" mnozina objektov sa skopiruje do oblasti 2, a vsetky objekty, na ktore sa da dostat z root setu sa tam skopiruju tiez, a tak dalej az po vsetky dosiahnutelne objekty. Potom sa alokuje uz iba do oblasti 2 (v oblasti 1 nam zostali objekty, ktore boli nedosiahnutelne, cela oblast sa oznaci za cistu), a ked sa 2ka zaplni, zase to iste do oblasti 1.
Describe the algorithm of a mark and sweep garbage collector.
běh programu se zastaví, naleznou se všechny „živé“ objekty metodou dosažitelnosti a následně se uvolní všechny „neživé“
A "mark and sweep" garbage collector maintains a bit (or two) with each object to record whether it is white or black; the grey set is either maintained as a separate list or using another bit. As the reference tree is traversed during a collection cycle, these bits are manipulated by the collector to reflect the current state. The mark and sweep strategy has the advantage that, once the unreachable set is determined, either a moving or non-moving collection strategy can be pursued; this choice of strategy can even be made at runtime, as available memory permits. It has the disadvantage of "bloating" objects by a small amount.
Describe the algorithm of a generational garbage collector. Assume knowledge of a basic copying garbage collector.
pozorování: 1) mnoho objektů se stane odpadem krátce po svém vzniku, a 2) jen malé procento referencí ve „starších“ objektech ukazuje na objekty mladší
garbage collector si paměť dělí na části - generace, objekty se začínají vytvářet jako nejmladší generace, v případě že se zaplní, všechny dosažitelné objekty se přesunou (označí) do starší generace
intervaly úklidů jsou různé pro různé generace, typicky velmi krátké pro nejmladší generaci, strategie úklidu může být různá pro různé generace
velmi pěkný článek o generational GC: http://www.ibm.com/developerworks/java/library/j-jtp11253/
It has been empirically observed that in many programs, the most recently created objects are also those most likely to quickly become unreachable (known as infant mortality or the generational hypothesis). A generational GC divides objects into generations and, on most cycles, will place only the objects of a subset of generations into the initial white (condemned) set. Furthermore, the runtime system maintains knowledge of when references cross generations by observing the creation and overwriting of references. When the garbage collector runs, it may be able to use this knowledge to prove that some objects in the initial white set are unreachable without having to traverse the entire reference tree. If the generational hypothesis holds, this results in much faster collection cycles while still reclaiming most unreachable objects.
Device Drivers
Popište obecnou architekturu ovladače zařízení a vysvětlete, jak tato architektura dovoluje zpracovávat současně asynchronní požadavky od hardware a synchronní požadavky od software.
Pro označení těchto dvou částí driveru se používají termíny bottom half (asynchronně volaná část driveru, která se stará převážně o požadavky hardware) a top half (synchronně volaná část driveru, která se stará převážně o požadavky software). Tento problém se řeší použitím mechanismů, které dovolují naplánovat na později vykonání operací, které jsou součástí obsluhy přerušení od hardware (v Linuxu bottom half handlers a tasklets, ve Windows deferred procedure calls, v Solarisu pinned interrupt thread pools).
Bottom half a top half většinou pracují přes fronty bufferů (občas mohou nastat problémy se zamykáním - obsluha přerušení od hw může běžet ve stejné chvíli jako obsluha přerušení od sw)
Popište obvyklý průběh obsluhy přerušení jako asynchronního požadavku na obsluhu hardware ovladačem zařízení. Průběh popište od okamžiku přerušení do okamžiku ukončení obsluhy. Předpokládejte obvyklou architekturu ovladače, kde spolu asynchronně a synchronně volané části ovladače komunikují přes sdílenou frontu požadavků. Každý krok popište tak, aby bylo zřejmé, kdo jsou jeho účastníci a kde získají informace potřebné pro vykonání daného kroku.
Windows kernel provides the option of postponing work done while servicing an interrupt through the deferred procedure call mechanism. The interrupt service routine can register a deferred procedure call, which gets executed later. The decision when to execute a deferred procedure call depends on the importance of the call, the depth of the queue and the rate of the interrupts.
Popište obvyklý průběh systémového volání jako synchronního požadavku na obsluhu software ovladačem zařízení. Předpokládejte obvyklou architekturu ovladače, kde spolu asynchronně a synchronně volané části ovladače komunikují přes sdílenou frontu požadavků. Průběh popište od okamžiku volání do okamžiku ukončení obsluhy. Každý krok popište tak, aby bylo zřejmé, kdo jsou jeho účastníci a kde získají informace potřebné pro vykonání daného kroku.
Nejsem si úplně jistý, co tu chce všechno mít, ale tak nástřel:
Uživ. vlákno vyvolá obslužnou funkci přes rozhraní systémových volání (syscall, int 80h, ...). Tím vstoupí do režimu jádra a zde zavolá potřebnou rutinu na ovladači zařízení.Ta vloží požadavek do fronty požadavků (což případně může znamenat nějaké čekání na zámku, protože o frontu se perou jak další procesy, které něco chtějí, tak asynchronní obsluha zařízení, která z ní tahá požadavky po vyřízení předchozích). Poté se volající vlákno uspí a čeká na vyřízení svého požadavku. Po vyřízení ho asynchronní obsluha přerušení vzbudí, vlákno případně ještě někam přeuloží získaná data, vrátí se z rutiny ovladače a opustí režim jádra.
Devices
List the features that a hardware device that represent a bus typically provides.
sběrnice = dráty + řadič
Parametry: datová šířka, kapacita, rychlost, technika přenosu - DMA
In computer architecture, a bus is a subsystem that transfers data or power between computer components inside a computer or between computers and typically is controlled by device driver software. Unlike a point-to-point connection, a bus can logically connect several peripherals over the same set of wires. Each bus defines its set of connectors to physically plug devices, cards or cables together.
Although busses are not devices in the usual sense, devices that represent busses are sometimes available to control selected features of the busses. Most notable are features for bus configuration.
Common features of busses include listing devices connected to the bus and drivers associated witthe bus, matching drivers to devices, hotplugging devices, suspend- ing and resuming devices.
List the features that a hardware clock device typically provides.
Využití hodin, kalendár, plánování procesu v preemptivním multitaskingu, účtování strojového času, alarmy pro user procesy, watchdogs pro systém, profilování, rízení.
Principy hodinového hardware, odvození od síte a od krystalového oscilátoru.
Možné funkce hardware, tedy samotný čítač, one time counter, periodic counter,
kalendár.
Využití hodinového hardware pro ruzné využití hodin - pro kalendár - pro plánování (ekvidistantní tiky, chce interrupt) - pro eventy (nastavování one time counteru je nejlepší, lze i jinak) - watchdog timer - profiling (bud statisticky koukat, kde je program, nebo presne merit).
List the features that a hardware keyboard device typically provides.
Klasický příklad character device. Klávesnice bez řadiče. Klávesnice s řadičem, překódování kláves, type ahead buffer, přepínání focusu. Keyboards are designed for the input of text and characters and also to control the operation of a computer.
List the features that a hardware mouse device typically provides.
Computer-users usually utilize a mouse to control the motion of a cursor in two dimensions in a graphical user interface.
List the features that a hardware terminal device with command interface typically provides.
Standardy řídících příkazů.
ANSI Escape Sequences třeba ESC [ <n> J (clear screen, 0 from cursor, 1 to cursor, 2 entire), ESC [ <line> ; <column> H (goto line and column), něco na barvy atd.
nejspíš se tímhle myslí čtení command line přes serial port - občas jediná možnost jak ziskat nejaky vystup z ruznych fw
List the features that a hardware terminal device with memory mapped interface typically provides.
Popis terminálů s memory mapped interface, znakové a grafické displeje, práce s video RAM, akcelerátory, hardwarová podpora kurzoru, kreslení apod.
připojení klasického monitoru přes vga,...
List the features that a hardware disk device typically provides.
A disk is a device that can read and write fixed length sectors. Various flavors of disks differ in how sectors are organized.
skladuje fixed length sektory, data, aj po vypnuti kompu, poskytuje read, write.
Možná by sem šlo započítat nějaký diskový řadič, který například umožňuje realizovat hw raid
Explain the properties that a hardware disk interface must have to support hardware ordering of disk access requests.
Podporuju ma vacsina SCSI a SATA diskov, avsak vacsina ATA diskov tuto podporu nemaju. Most versions of the ATA interface do not support issuing a new request to the disk before the previous request is completed, and therefore cannot implement any strategy to process the queue of requests. On the contrary, most versions of the SCSI and the SATA interfaces do support issuing a new request to the disk before the previous request is completed.
EDIT: Jaké parametry takový hardware musí mít? No musí umět přijímat nové requesty, zatímco nějaký zpracovává. Musí mít nějaké vnitřní buffery a reorder jednotku.
Describe at least three strategies for ordering disk access requests. Evaluate how the strategies optimize the total time to execute the requests.
The FIFO strategy of processing requests directs the disk to always service the first of the waiting requests. The strategy can suffer from excessive seeking Gross tracks.
The Shortest Seek First strategy of processing requests directs the disk to service the request that has the shortest distance from the current position of the disk head. The strategy can suffer from letting too distant requests starve.
The Bidirectional Elevator strategy of processing requests directs the disk to service the request that has the shortest distance from the current position of the disk head in the selected direction, which changes when no more requests in the selected direction are waiting. The strategy lets too distant requests starve at most two passes over the disk in both directions.
Explain the role of a disk partition table.
Diskové oddíly slouží k rozdělení fyzického disku na logické oddíly, se kterými je možné nezávisle manipulovat. Rozdělení fyzického disku na logické diskové oddíly bývá uvedeno v tzv. Partition Table, která se nachází na úplně prvním sektoru disku (tzv. Master boot record). Nejčastější verze této tabulky umožňuje pouze čtyři záznamy, ale v případě většího
počtu diskových oddílů na jednom médiu je možné v hlavní (primární) tabulce odkázat na takzvaný rozšířený diskový oddíl (extendend partition), na jehož začátku se opět nachází MBR s další tabulkou,
ve které je uvedeno rozdělení extended partition na další oddíly.